
 |
柴田克成のホームページへようこそ! ★English version is here. ★文献等はこちら |
Google DeepMind のHassabisらの素晴らしい成果により,この分野が急激に注目を集めています.
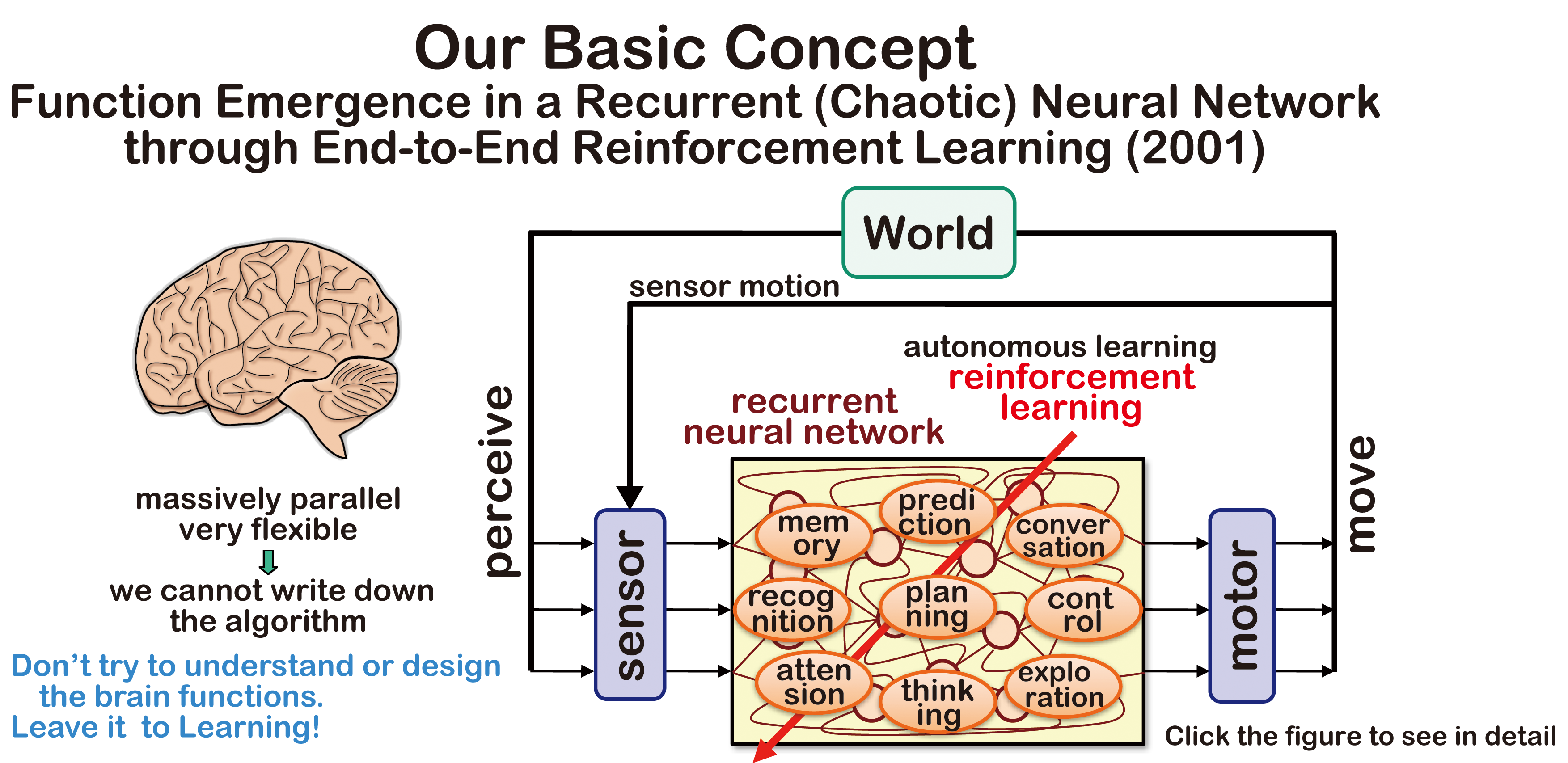
センサからモータまでをニューラルネットで構成し,強化学習させることは,
当研究室のオリジナルのアイデアです(20年ほど前から提起しています).
このアプローチで実ロボットへも適用し,さらにリカレントネット(RNN)も使い(ここ),
記憶,予測,コミュニケーションなどのさまざまな機能が創発することも示してきました.
われわれの研究はほとんど認知されておりませんので,
皆様の論文等へ引用していただけると幸いです (_O_)
また,これからの高次機能創発への鍵はカオスニューラルネット
と考えて現在研究しています(ここ).
<実ロボットへの適用>
AIBOキスタスク (2008)
画像信号入力の Deep Q Network を実ロボットに適用! (世界初)
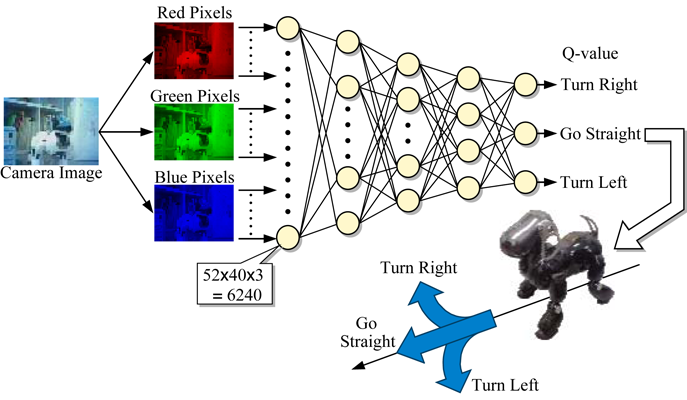
6240個の生の画像信号を入力した5層のQネットワーク (DQN)
キスした時の報酬と見失った時の罰だけで,相手のAIBOの認識と行動を学習
ただし,畳み込みネットワークは使用しておらず,層間全結合です.
ICONIP2008 英語論文
一つ前のタスクの論文(中間層の解析が面白いので載せます)
FAN08 日本語論文
視覚化した重み値データはこちら.
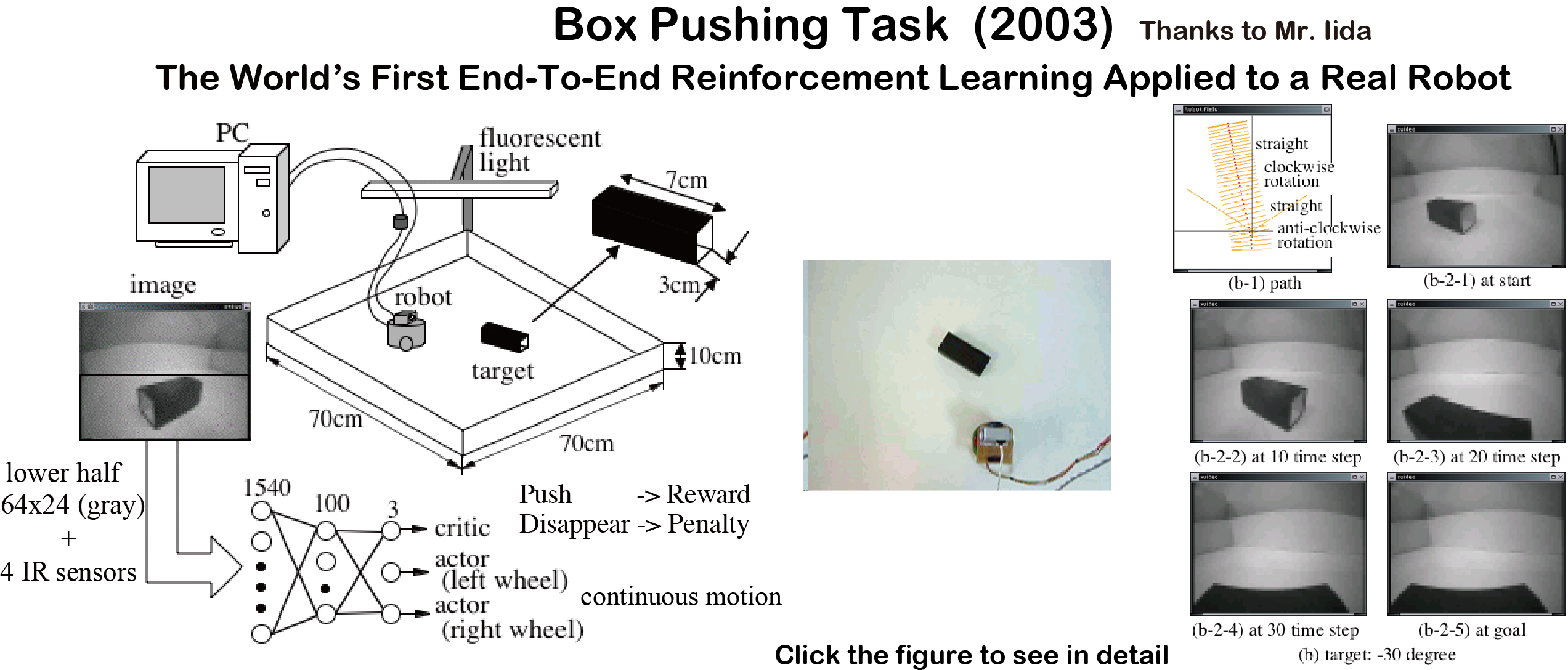
箱押しタスク(2003)
画像信号入力の強化学習を実ロボットに適用 (世界初)
1540個のグレースケールの画像信号を3層のニューラルネットに入力して
箱を押した時の報酬だけから強化学習
連続状態,行動空間のためActor-Criticを利用.
SICE2003 英語論文
FAN04 日本語論文
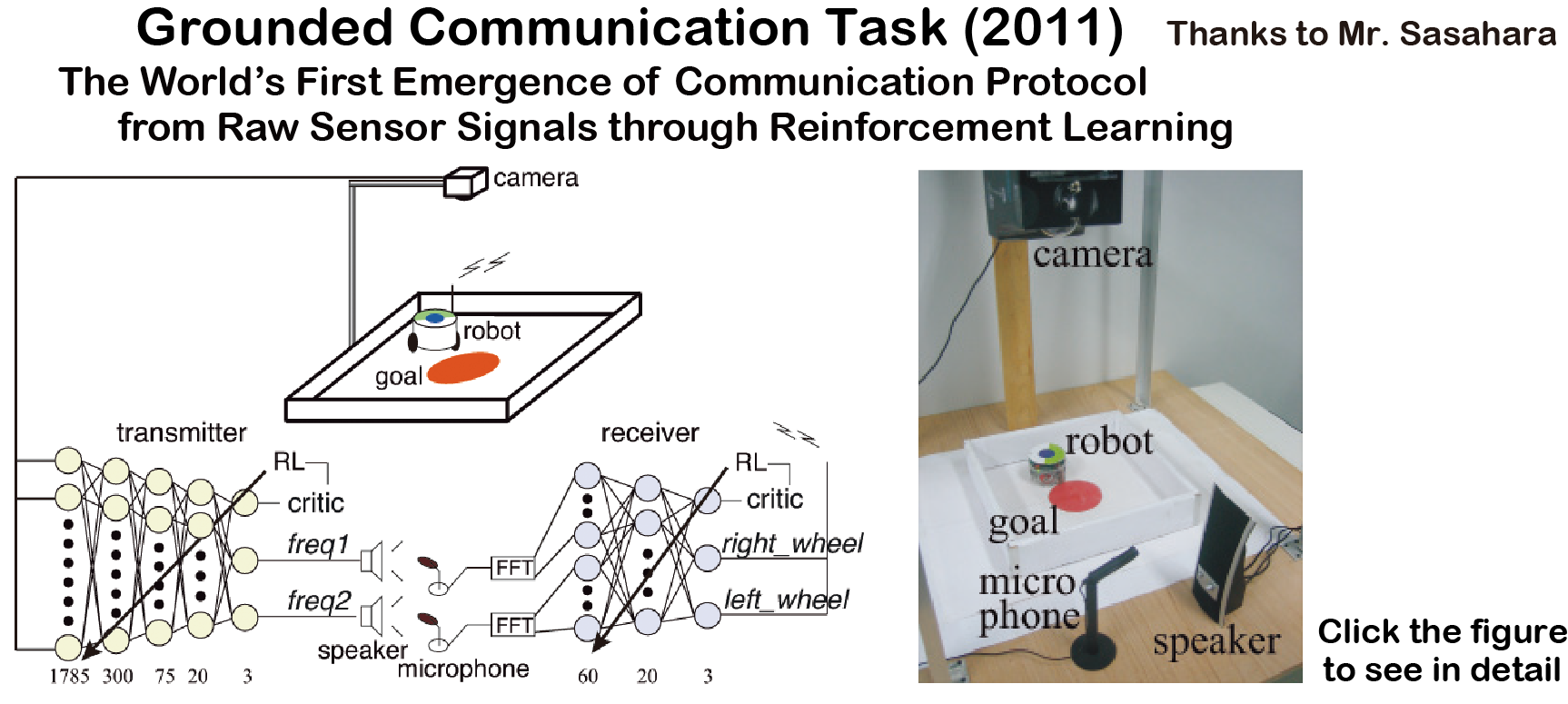
接地コミュニケーションタスク(2011)
強化学習による画像入力コミュニケーション! (世界初)

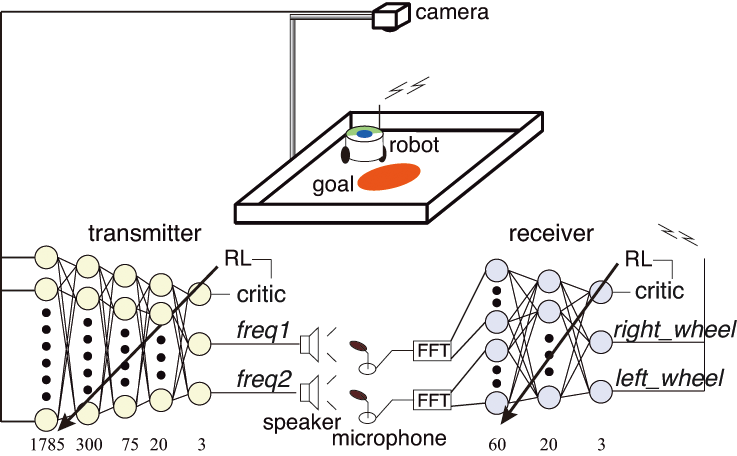
送信者(5層):画像入力,音声出力,受信者(3層):音声入力,ロボット制御信号出力
ロボットがゴールするために必要な音声コミュニケーションを強化学習で獲得
ICONIP2011 英語論文
SSI2012 日本語論文
視覚センサ信号入力の深層強化学習(世界初)
JNNS1996 日本語論文
ICNN1997 英語論文
先行研究がありましたら,shibata[at]oita-u.ac.jp までご連絡ください.
<研究の方針とまとめ>
(脳の機能を理解しようとしてはいけない!?)
柴田克成:
強化学習とニューラルネットによる知能創発, 計測と制御, Vol. 48, No. 1, pp. 106-111, 2009.1
pdf File (6pages, 800kB)
追加のデータ等は
こちらへ。
Katsunari Shibata:
Emergence of Intelligence through Reinforcement Learning with a Neural Network,
Advances in Reinforcement Learning, Abdelhamid Mellouk (Ed.), InTech, pp.99-120, 2011. 2.
here
<深層強化学習に関連した研究(視覚信号を入力とし,内部表現を観察)>
(生の視覚信号を入力とした強化学習を主張した論文誌の論文, シミュレーション, 2001)
柴田克成, 岡部洋一, 伊藤宏司:
ニューラルネットワークを用いたDirect-Vision-Based強化学習 −センサからモータまで−,
計測自動制御学会論文集, Vol.37, No.2, pp.168-177, 2001.2
pdf File (10 pages, 307kB)
(色恒常性の創発, 2012)
柴田克成, 栗崎俊介:
ニューラルネットを用いた強化学習による行動の学習を通した 色恒常性の創発,
電子情報通信学会技術報告, NC2012-171, pp.215-220, 2013.3
pdf File (6pages, 2.3MB)英語の論文あり
<腕のリーチング動作の創発>
(道具使用時の内部表現, 2003)
Katsunari Shibata & Koji Ito:
Hidden Representation after Reinforcement Learning of Hand Reaching Movement with Variable Link Length,
Proc. of IJCNN (Int'l Joint Conf. on Neural Networks) 2003, 1475-674.pdf, pp.2619-2624, 2003. 7
pdf File (6 pages, 764kB)
(Hand Reaching, 2002)
柴田克成, 杉坂政典, 伊藤宏司:
強化学習によるリーチング運動の獲得,
電子情報通信学会技術研究報告, NC2000-170, pp. 107-114, 2001. 3.
pdf File (8 pages, 318kB)
<リカレントネットを用いた面白い機能の創発>
(視覚センサ信号入力ではないが非常に面白い行動の創発, 2009)
Hioroki Utsunomiya and Katsunari Shibata:
Contextual Behavior and Internal Representations Acquired by Reinforcement Learning with a Recurrent Neural Network in a Continuous State and Action Space Task,
Advances in Neuro-Information Processing, Lecture Notes in Computer Science,
Proc. of ICONIP (Int'l Conf. on Neural Information Processing) 08,
Vol. 5507, pp. 970--978, 5507-0970.pdf (CD-ROM), 2009
pdf File (9pages, 472kB)
(予測と予想外の状況への対処行動の創発, 2013)
柴田克成, 後藤健太:
予測を要して連続動作を含む柔軟な行動のActor-Q学習による獲得,
第23回インテリジェント・システム・シンポジウム (FAN 2013) 講演論文集, pp. 86-91, 2013. 9
pdf file (6 pages, 762KB)英語の論文あり
(ノイズ付加によるコミュニケーション信号の離散化, 2005)
柴田克成:
なんと,コミュニケーション信号にノイズを付加して学習すると,
その信号が勝手に2値化する!
コミュニケーションの強化学習におけるノイズ付加による連続値信号の離散化,
電子情報通信学会技術研究報告, Vol. 103, No. 734, NC2003-203, pp. 55-60, 2004. 3
pdf File (6 pages, 204kB)英語の論文あり
(センサー動作,能動認識の創発, Actor-Q-learning, 2014)
A.A.M. Faudzi and Katsunari Shibata:
Acquisition of Context-Based Active Word Recognition by Q-Learning Using a Recurrent Neural Network,
J.-H. Kim et al. (eds.), Robot Intelligent Technoloy and Application, Vol. 2, Advances in Intelligent System and Computing, 274, pp. 191-200, 2014.4
pdf file (10 pages, 1.7MB)
(連想記憶の創発, 2001)
柴田 克成, 伊藤 宏司:
認識の学習に基づく注意と連想記憶の形成,
電子情報通信学会技術研究報告, NC99-137, pp. 153-160, 2000. 3.
pdf File (8 pages, 103kB)英語の論文あり
<時間軸に注目した学習 (カオスや因果関係の利用,現在の研究の中心)>
(カオス探索と思考の創発へのブレークスルー)
柴田克成,坂下悠太:
カオスニューラルネットを用いた内部ダイナミクス由来の探索に基づく強化学習,
電子情報通信学会技術報告, NC2014-117, pp.277-282, 2015.3
pdf file (6 pages,649KB)英語の論文あり
(因果トレース, 主観的時間スケール 2014)
柴田克成:
因果トレース - 並列かつ主観的時間スケールの導入による過去の処理の効率的学習 -,
電子情報通信学会技術報告, NC2013-115, pp.157-162, 2014.3
pdf file (6 pages, 475KB)英語の論文あり
<その他の研究>
(成長型ニューラルネット, 誤差信号の拡散によって軸索が成長, 2004)
栗野竜輔, 柴田克成:
隠れニューロンの分離を伴う成長型ニューラルネットワーク,
電子情報通信学会技術研究報告, Vol. 103, No. 734, NC2003-212, pp. 109-114, 2004. 3
pdf File (6 pages, 1.08MB)英語の論文あり
謝辞
これらの研究は,われわれの研究室の仲間と一緒にやってきた成果です。
ここに名前が出ていない人もいますが,上の成果は,すべての研究室のメンバーによって
作られた基礎の上に行われたものです。研究室のメンバーに深く感謝します。
Ray Kurzweilのように,2045年頃には,人間の知性を越えるロボットが誕生するとの話もありますが,
私は,人間の知能の実現にはまだまだ乗り越えなければならない壁が多々あり,今のカーブで
コンピュータの計算能力が上がるからといって,そう簡単に人間のような知性が実現できる
とは思っていません。
しかし,ロボットが本当に賢くなって,人間がコントロールできないところにいったら,
本当に役に立つどころか,当然危険であると言わざるをえません。
このような問題は,Bill Joy が指摘している GNR (genetics, nanotechnology and robotics)や
核の問題のように,自己増殖型技術に内在する重大な問題点だと思います。
自分で研究を進めておきながら,そこにある危険を指摘するのは矛盾していると思われるでしょう。
実際に自分自身,非常に悩むところです。
本当はこれらの研究はすべて今すぐ止めるべきだと思っていますが,そう言って,実際にすべての
研究がストップするわけでなく,当然自分がやらなくても誰かが研究するでしょう。
現実的な解として,いち早く具体的な警告を発せられることが重要であると考えています。
もっとも,現時点では,ロボットの知性についてはまだまだ考えるに値しないレベルであると
思っているから,研究を進めているという面もあります。
このような研究を大学で学生諸君と役に立つようなふりをしながら実施することには無理があることもあり、
大学を早期退職することといたしました。