
 |
Thank you for Visiting Katsunari Shibata's Home Page Japanese version is here. Last update was done on Oct. 20, 2016 |
Thanks to the wonderful results by Hassabis et al. in
Google DeepMind,
this field (RL+NN) is now suddenly attracting attention.
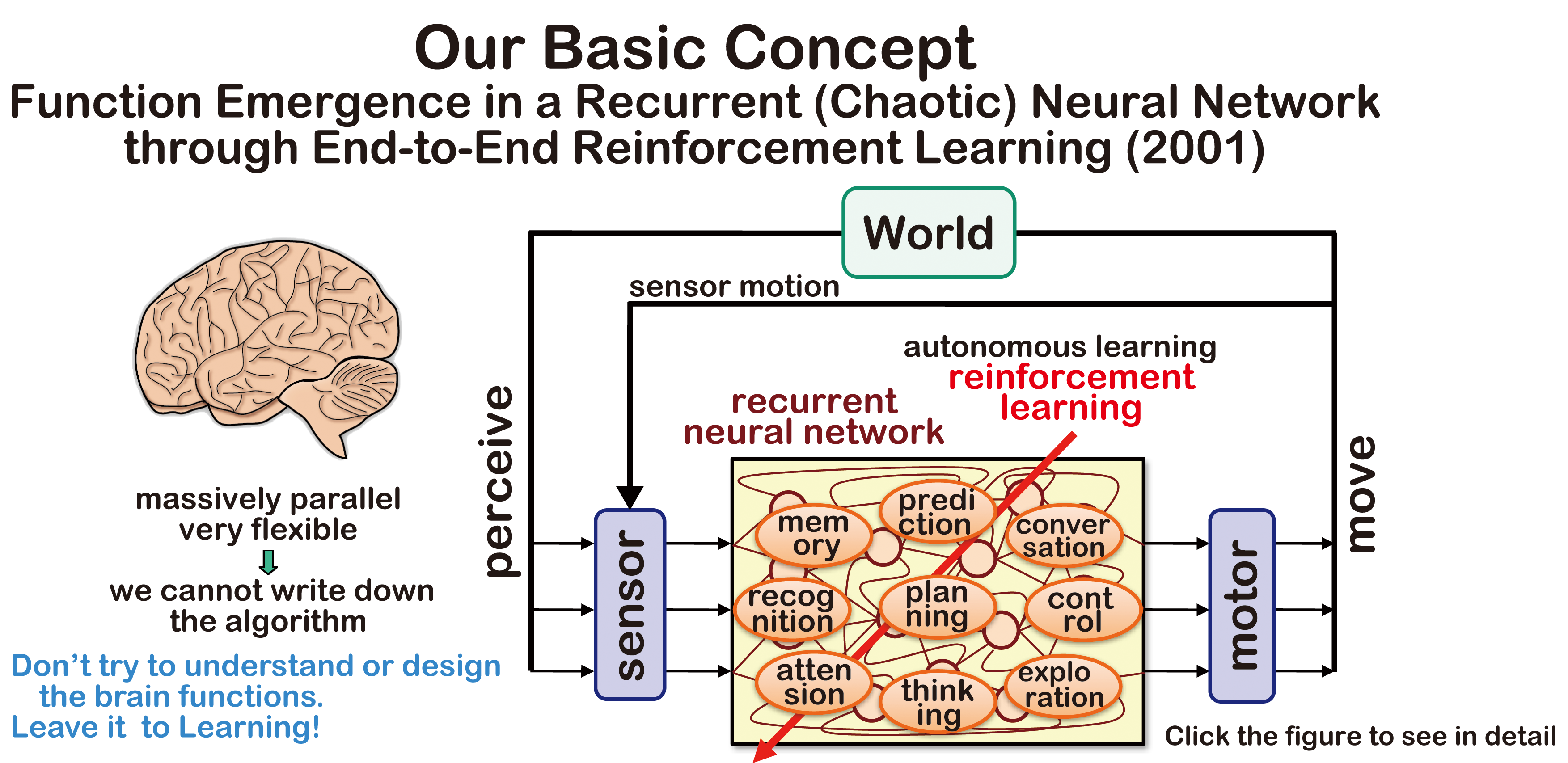
End-to-end reinforcement learning using a neural network
(from sensors to motors) is our original idea
We have many works from the viewpoint of what function emerges in this framework, but they have not been recognized well.
Thank you for referring them in your papers!
Choosing one of the following items takes you to your preferred part.
| Real Robot Applications with Raw Pixel Image Inputs | Click HERE |
| Emergence of Communications (Signal Discretization, Grounded Communication, Dynamic Communication) |
Click HERE |
| Higher Function Emergence Using a Recurrent Neural Network (RNN) (Memory, Prediction, Exploration, Attention, Other Contextual Bahaviors) |
Click HERE |
| Function Emergence Using a Layered Neural Network (Color Constancy, Hand Reaching (Hand-Eye Coordination), Tool Use, Sensor Motion) |
Click HERE |
| Concept & Overview | Click HERE |
| RL with Chaotic NN Aiming to the Emergence of THINKING | Click HERE |
| Other Works | Click HERE |
| Early works in RL+NN | Click HERE |
<Real Robot Application>
Kissing AIBO task (2008)
The world's first Deep Q Network applied to a Real Robot!
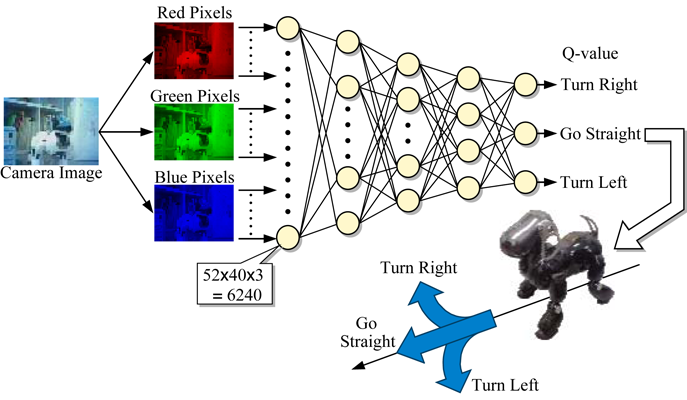
6,240 raw RGB image signals are put into a 5 layer Q-network
From only the reward for kiss and penalty for disapperance of the target AIBO,
the AIBO learns to recognize the target AIBO and go toward it.
ICONIP2008 paper
The following paper is for the previous task, but the analysis of hidden representation is interesting.
JCMSI paper
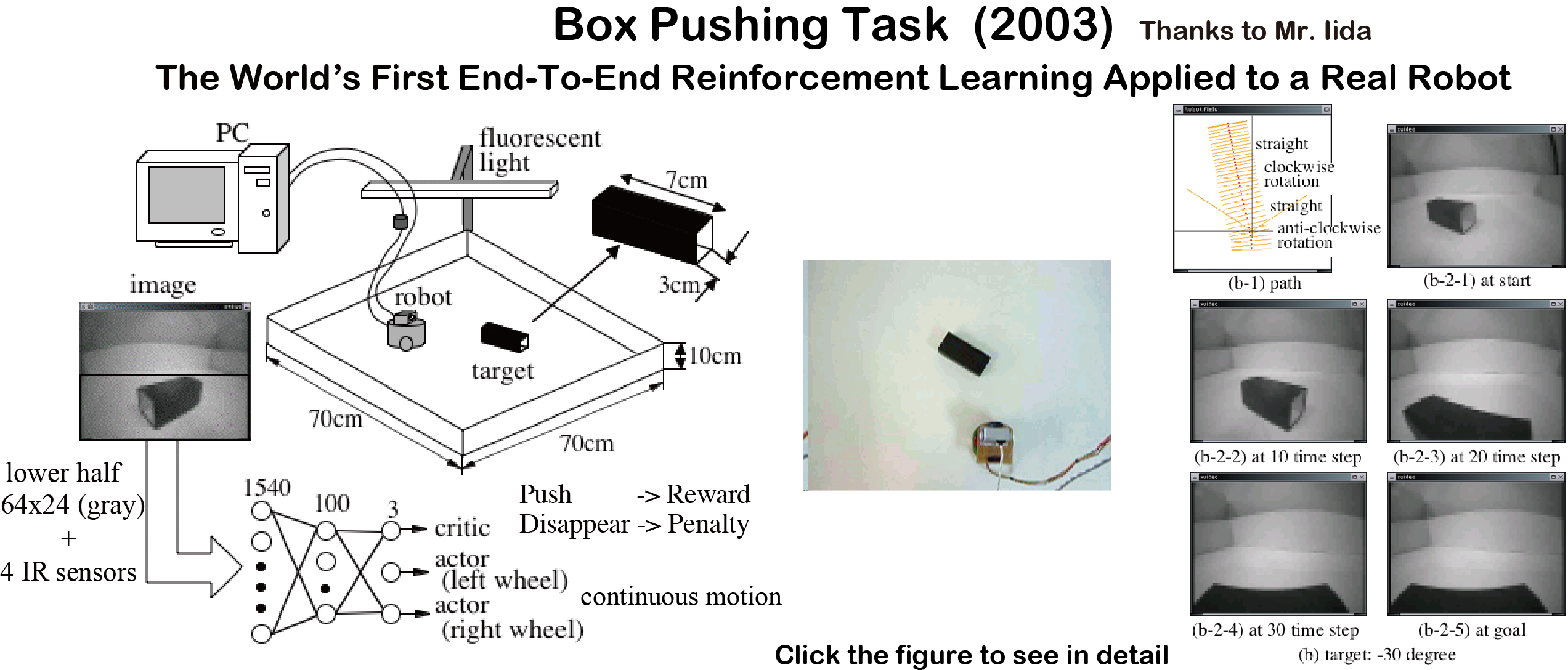
Box-pushing task(2003)
The world's first end-to-end reinforcement learning in a real robot!

Not deep but 3 layer neural network with 1540 raw gray-scale pixel inputs
Actor-Critic in continuous sensor and motor spapce.
SICE2003 paper
<Emergence of Communication>
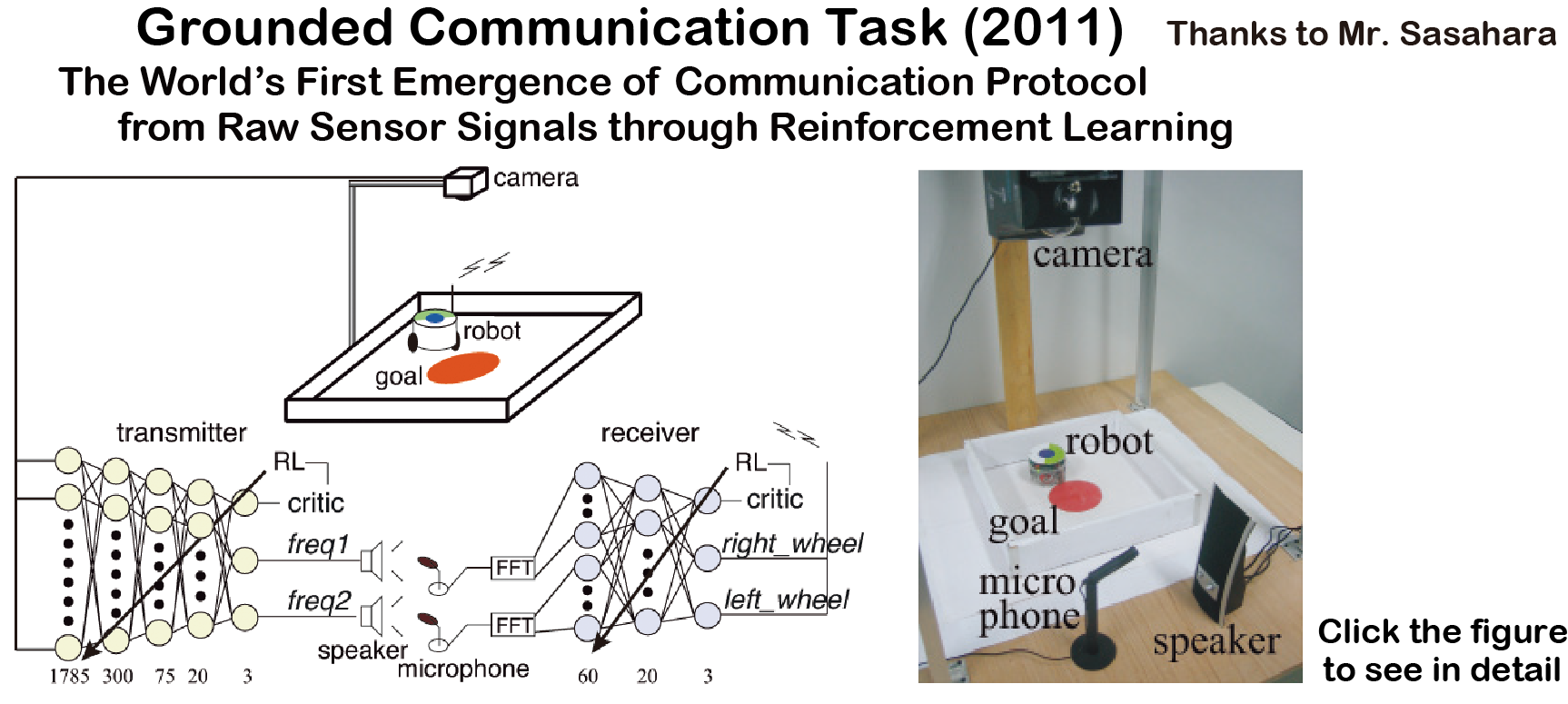
Grounded Communication Task (2011)
The world's first Grounded Communication through reinforcement learning in a real robot!

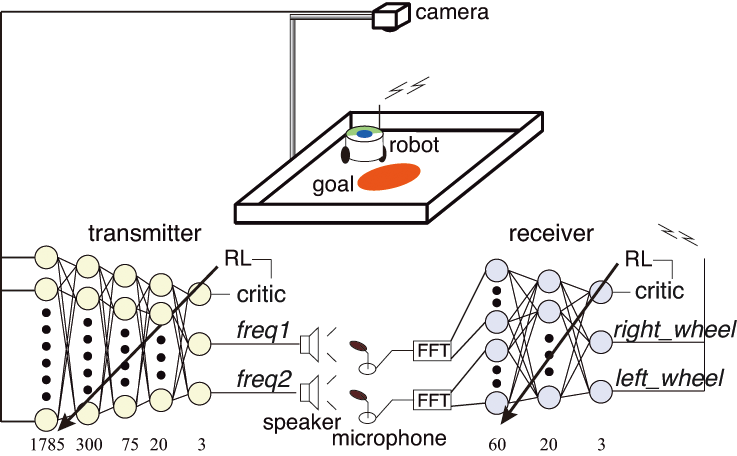
Communication protocol is not given in advance
Completely Independent Learning (No information is communicated between the agents)
Reward is given to both agents when the robot reaches the red area.
Transmitter(5layer): Image inputs (so we can say "Grounded"), Sound outputs
Receiver(3layer): Sound inputs, Motion command outputs
Appropriate sound communication to move the robot to the goal
is acquired through reinforcement learning.
ICONIP2011 paper
Discretization of Communication Signal (2005)
Continuous communication signal is discretised autonomously through reinforcement learning
in a noisy environment without any directions!



Transmitter (cannot move): Input: Location of the receiver, Output: Continuous signal
Receiver (cannot see): Input: The signal from the transmitter, Ouput: Move (in one-dimensional space)
Communication: Two continuous signals are sent one by one (t=1, t=2) through one channel
Receiver has to understand the distance from the two successive signals using its RNN.
Reward: The distance between the agents is smaller than 0.11.
The location of the receiver is represented two bit binary signal as above in noisy environment.
ICANNGA 2005 paper
Dynamic Communication (Negotiation)(1999)
Learning of 3 communication chances to avoid conflict.




4 agents are picked up randomly among 8 agents at each episode.
3 communication chances are given, and -1 or 1 is chosen as a signal according to the com output.
At each chance, the agents can receive the 4 signals including their own signal that are input of the RNN.
After 3 communication chances, each agent has to choose which path to go circle(1) or triangle(-1).
No conflict -> reward, Conflict -> penalty
Sample negotiation after learning are shown above.
Individuality emerge among the agenet as above.
ISADS 1999 paper
<Early works>
The world's first end-to-end deep reinforcement learning
ICNN1997 paper
<Concept and Overview of Our Research>
(Don't try to understand the Brain Functions!?)
Katsunari Shibata:
Emergence of Intelligence through Reinforcement Learning with a Neural Network,
Advances in Reinforcement Learning, Abdelhamid Mellouk (Ed.), InTech, pp.99-120, 2011. 2.
here
<Emergence of Static Functions>
Emergence of Color constancy (2012)
Katsunari Shibata and Shunsuke Kurizaki:
Emergence of Color Constancy Illusion through Reinforcement Learning with a Neural Network,
Proc. of ICDL-EpiRob (Int'l Conf. on Development and Learning - Epigenetic Robotics) 2012, PID2562951.pdf, 2012. 11
pdf File (6 pages, 1.6MB)
(Emergence of Hand-Eye Coordination & Reaching Arm Movement)
Internal Representation for Tool use (2003)
Katsunari Shibata & Koji Ito:
Hidden Representation after Reinforcement Learning of Hand Reaching Movement with Variable Link Length,
Proc. of IJCNN (Int'l Joint Conf. on Neural Networks) 2003, 1475-674.pdf, pp.2619-2624, 2003. 7
pdf File (6 pages, 764kB)
Hand-Eye Coordination and Reaching Movement (2002)
Katsunari Shibata & Koji Ito:
Effect of Force Load in Hand Reaching Movement Acquired by Reinforcement Learning,
Proc. of Int'l Conf. on Neural Information Processing Systems (ICONIP '02), Vol. 3, pp. 1444-1448, 2002.11
pdf File (5 pages, 200kB)
<Higher Functions using a Recurrent Neural Network>
Very interesting behavior (2009)
Hioroki Utsunomiya and Katsunari Shibata:
Contextual Behavior and Internal Representations Acquired by Reinforcement Learning with a Recurrent Neural Network in a Continuous State and Action Space Task,
Advances in Neuro-Information Processing, Lecture Notes in Computer Science,
Proc. of ICONIP (Int'l Conf. on Neural Information Processing) 08,
Vol. 5507, pp. 970--978, 5507-0970.pdf (CD-ROM), 2009
pdf File (9pages, 472kB)
Prediction and Reaction to unexpected situation (2013)



Learning of catching an moving object that sometimes becomes invisible after a while from start.
The initial location, speed and angle of the object are set randomly at each episode.
Both the timing and location for catch have to be learned.
Flexible response for sudden motion change is also required.
Katsunari Shibata and Kenta Goto:
Emergence of Flexible Prediction-Based Discrete Decision Making and Continuous Motion Generation through Actor-Q-Learning,
Proc. of Int'l Conf. on Development and Learning and on Epigenetic Robotics (ICDL-Epirob) 2013, ID 15 (CDROM) 2013. 8
pdf file (6 pages, 684KB)
Discretization of Communication Signal by Noise Addition, (2005)
Katsunari Shibata:
Discretization of Series of Communication Signals in Noisy Environment by Reinforcement Learning,
Ribeiro et al(eds.), Adaptive and Natural Computing Algorithms, Proc. of the 7th Int'l Conf. in Adaptive and Natural Computing Algorithms (ICANNGA'05), pp. 486-489, 2005. 3
pdf File (4 pages, 224kB)
Emergence of Sensor motion, Active Perception and Recognition, Actor-Q-learning (2014)
A.A.M. Faudzi and Katsunari Shibata:
Acquisition of Context-Based Active Word Recognition by Q-Learning Using a Recurrent Neural Network,
J.-H. Kim et al. (eds.), Robot Intelligent Technoloy and Application, Vol. 2, Advances in Intelligent System and Computing, 274, pp. 191-200, 2014.4
pdf file (10 pages, 1.7MB)
Katsunari Shibata, Tetsuo Nishino & Yoichi Okabe:
Active Perception and Recognition Learning System Based on Actor-Q Architecture,
J.-H. Kim et al. (eds.), Robot Intelligent Technoloy and Application, Vol. 2, Advances in Systems and Computers in Japan, Vol. 33, No. 14, pp. 12-22, 2002. 12
pdf file (11 pages, 5.6MB)
Emergence of Exploration
Learning of exploration for an unseen goal.
Kenta Goto and Katsunari Shibata:
Acquisition of Deterministic Exploration and Purposive Memory through Reinforcement Learning with a Recurrent Neural Network,
Proc. of SICE Annual Conf. 2010, FB03-1.pdf, 2010. 8
pdf file (7 pages, 312KB)
The effect that learning in one room gives to the learning in 4 rooms environment was observed.
Deterministic exploration behavior acquired through reinforcement learning can be considered as temporal abstract actions.
Katsunari Shibata:
Learning of Deterministic Exploration and Temporal Abstraction in Reinforcement Learning,
Proc. of SICE-ICCAS (SICE-ICASE Int'l Joint Conf.), pp. 4569-4574, 2006. 10
pdf file (6 pages, 462B)
Knowledge Transfer
Katsunari Shibata:
Spatial Abstraction and Knowledge Transfer in Reinforcement Learning Using a Multi-Layer Neural Network,
Proc. of ICDL5 (Fifth Int'l Conf. on Development and Learning) 2006, 36 (CD-ROM), 2006. 5BR>
pdf file (6 pages, 712B)
Emergence of Attention and Associative Memory (2001)
Katsunari Shibata:
Formation of Attention and Associative Memory Based on Reinforcement Learning,
Proc. of ICCAS (Int'l Conf. on Control, Automation and Systems) 2001, pp. 9-12, 2001. 10
pdf File (4 pages, 136kB)
<Learning of Temporal Events (Using Chaos or Causality)>
Completely Novel Reinforcement Learning Using a Chaotic Neural Network, expecting to be the Breakthrough for emergence of "Thinking" (2015)
Katsunari Shibata and Yuta Sakashita:
Reinforcement Learning with Internal-Dynamics-based Exploration Using a Chaotic Neural Network,
Proc. of Int'l Joint Conf. on Neural Networks (IJCNN)2015, 2015.7
pdf file (8 pages, 843KB)
More Effective memory than Eligibility Trace, Subjective Time Scale (2014)
Katsunari Shibata:
Causality Traces for Retrospective Learning in Neural Networks - Introduction of Parallel and Subjective Time Scales -,
Proc. of Int'l Joint Conf. on Neural Networks, P542 (CD-ROM) , 2014.7
pdf file (8 pages, 302KB)
<Other Works>
Growing Neural Network, Axon grows according to Diffused Error signals , 2004)
Ryusuke Kurino, Masanori Sugisaka & Katsunari Shibata:
Growing Neural Network with Hidden Neurons,
Proc. of The 9th AROB (Int'l Sympo. on Artificial Life and Robotics), Vol. 1, pp. 144-147, 2004. 1
pdf File (4 pages, 191kB)
Acknowledgement
Those works have been done by the cooperation of my colleagues.
There are many ones whose name is not in the above, but the above works were done by the basis that all the members have worked.
Katsunari Shibata